
- The types of probabilistic objects that gradients are taken with respect to.
- Why we might want / need an estimator for the above
So what exactly are we taking gradients of? In the paper the authors introduce this object as “a general probabilistic objective” (note, for the remainder of this blog post, that all lowercase non-bold symbols except for the index variable n should be considered vector-valued quantities):
![\mathcal{F(\mathbf{\theta})} := \int p(x; \theta)f(x; \phi)dx = \mathop{\mathbb{E}}_{p(x; \theta)}\Big[f(x; \phi)\Big] \qquad (1) \bigskip](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BF%28%5Cmathbf%7B%5Ctheta%7D%29%7D+%3A%3D+%5Cint+p%28x%3B+%5Ctheta%29f%28x%3B+%5Cphi%29dx+%3D+%5Cmathop%7B%5Cmathbb%7BE%7D%7D_%7Bp%28x%3B+%5Ctheta%29%7D%5CBig%5Bf%28x%3B+%5Cphi%29%5CBig%5D+%5Cqquad+%281%29+%5Cbigskip&bg=ffffff&fg=333333&s=0&c=20201002)
In (1) we notice that the objective involves integrating over all the possible values
 can become. Now if you’re at all familiar with topics in any theory/computational orientated subject you’ll recognize that integrating (1) might be rather difficult, if not impossible. With the usual culprits of having no closed form evaluation of the integral (as opposed to say
can become. Now if you’re at all familiar with topics in any theory/computational orientated subject you’ll recognize that integrating (1) might be rather difficult, if not impossible. With the usual culprits of having no closed form evaluation of the integral (as opposed to say  for which we do have a closed form evaluation), and or issues regarding the large space of values that variables of interest can take, thus making approximation by quadrature ineffective. These reasons tell us we will need some other type of approximation. That approximation will be a Monte Carlo estimator of the expectation. Generally we can define this estimator, given samples
for which we do have a closed form evaluation), and or issues regarding the large space of values that variables of interest can take, thus making approximation by quadrature ineffective. These reasons tell us we will need some other type of approximation. That approximation will be a Monte Carlo estimator of the expectation. Generally we can define this estimator, given samples 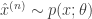 for
for 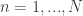 as (note that we are using approximately below to guide intuition, this is not the usual use of it):
as (note that we are using approximately below to guide intuition, this is not the usual use of it):
![\mathop{\mathbb{E}}_{p(x; \theta)}\Big[f(x; \phi)\Big] \approx \mathcal{\bar F}_N = \bigskip \frac{1}{N} \sum_{n=1}^N f\Big(\hat x^{(n)} \Big) \qquad (2)](https://s0.wp.com/latex.php?latex=%5Cmathop%7B%5Cmathbb%7BE%7D%7D_%7Bp%28x%3B+%5Ctheta%29%7D%5CBig%5Bf%28x%3B+%5Cphi%29%5CBig%5D+%5Capprox+%5Cmathcal%7B%5Cbar+F%7D_N+%3D+%5Cbigskip+%5Cfrac%7B1%7D%7BN%7D+%5Csum_%7Bn%3D1%7D%5EN+f%5CBig%28%5Chat+x%5E%7B%28n%29%7D+%5CBig%29+%5Cqquad+%282%29&bg=ffffff&fg=333333&s=0&c=20201002)
One last thing that we’ll come back to later on. We note that the subject of the article and this blog post is “Monte Carlo gradient estimator”, however above I’ve outline why you might want a Monte Carlo estimator of an expectation. These two things are not necessarily the same. The gradient of the expectation is not simply the expectation of the gradient (obtained by exchanging the order of integration and differentiation), at least when the gradient is taken with respect to the parameters of the distribution itself. To make this work, we will make use of ideas from probability and statistics to write down the gradient of the expectation again as a proper expectation — thus allowing us to approximate said expectation with a Monte Carlo estimator.
So we have the thing to approximate, how we’re going to approximate it, and know what are the computational difficulties that call for an approximation to be made. What’s left is to motivate where we’d use this approximation. In short, (please refer to the original papers!) policy gradient (think reinforcement learning .i.e. Sutton & Barto), and Black Box Variational Inference both make use of what’s been outlined above (though there are other use cases!).
Both methods need to learn some set of parameters . One way to learn such parameters is through gradient descent. So we will need the gradient of the objective (which we have defined above as the expectation), which is (as usual):
. One way to learn such parameters is through gradient descent. So we will need the gradient of the objective (which we have defined above as the expectation), which is (as usual):
![\nabla_{\theta}\mathbb{E}_{p(x; \theta)}[f(x; \phi)] \qquad (3)](https://s0.wp.com/latex.php?latex=%5Cnabla_%7B%5Ctheta%7D%5Cmathbb%7BE%7D_%7Bp%28x%3B+%5Ctheta%29%7D%5Bf%28x%3B+%5Cphi%29%5D+%5Cqquad+%283%29&bg=ffffff&fg=333333&s=0&c=20201002)
This now calls us to refine our words a bit. We’re not trying to arrive at a Monte Carlo estimator of the expectation per-se, rather we want a Monte Carlo estimator of the gradient of that expectation. This is where the score function estimator and the pathwise estimator come into play. The score function is defined as the gradient of the log of the function
 . Thus it is (by the chain rule of differentiation):
. Thus it is (by the chain rule of differentiation):

This is useful because it is an expression relating the gradient of the function of interest
to the gradient of its log. That’s good to know but why is it useful for what we hope to accomplish? This becomes clearer if we write out the gradient of the expectation (under conditions that allow the interchange of integration and differentiation):
![\nabla_{\theta} \mathbb{E}_{p(x; \theta)}[f(x; \phi)] = \nabla_{\theta} \int p(x; \theta)f(x; \phi) dx = \int f(x; \phi) \nabla_{\theta}p(x; \theta) dx \qquad (4)](https://s0.wp.com/latex.php?latex=%5Cnabla_%7B%5Ctheta%7D+%5Cmathbb%7BE%7D_%7Bp%28x%3B+%5Ctheta%29%7D%5Bf%28x%3B+%5Cphi%29%5D+%3D+%5Cnabla_%7B%5Ctheta%7D+%5Cint+p%28x%3B+%5Ctheta%29f%28x%3B+%5Cphi%29+dx+%3D+%5Cint+f%28x%3B+%5Cphi%29+%5Cnabla_%7B%5Ctheta%7Dp%28x%3B+%5Ctheta%29+dx+%5Cqquad+%284%29&bg=ffffff&fg=333333&s=0&c=20201002)
note now that the goal is to arrive at a Monte Carlo estimator of the expectation, however in (4) the right most side of you’ll note that we no longer have an expectation. This is because
has become 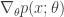 , and the gradient does not in general satisfy the conditions to be considered a proper probability (e.g. the gradient can be negative!). However, due to the expression given by the definition of the score function, we can replace by
, and the gradient does not in general satisfy the conditions to be considered a proper probability (e.g. the gradient can be negative!). However, due to the expression given by the definition of the score function, we can replace by  . Plugging this back in the the right most side of (4) we have:
. Plugging this back in the the right most side of (4) we have:
![\int f(x; \phi)p(x; \theta)\nabla_{\theta} \log p(x; \theta) = \int p(x; \theta) [f(x; \phi) \nabla_{\theta} \log p(x; \theta)] = \mathbb{E}_{p(x; \theta)} [f(x; \phi)\nabla_{\theta} \log p(x; \theta)]](https://s0.wp.com/latex.php?latex=%5Cint+f%28x%3B+%5Cphi%29p%28x%3B+%5Ctheta%29%5Cnabla_%7B%5Ctheta%7D+%5Clog+p%28x%3B+%5Ctheta%29+%3D+%5Cint+p%28x%3B+%5Ctheta%29+%5Bf%28x%3B+%5Cphi%29+%5Cnabla_%7B%5Ctheta%7D+%5Clog+p%28x%3B+%5Ctheta%29%5D+%3D+%5Cmathbb%7BE%7D_%7Bp%28x%3B+%5Ctheta%29%7D+%5Bf%28x%3B+%5Cphi%29%5Cnabla_%7B%5Ctheta%7D+%5Clog+p%28x%3B+%5Ctheta%29%5D+&bg=ffffff&fg=333333&s=0&c=20201002)
which brings us back into the realm of computing a proper expectation and we can now use (2) to write down the form of the estimator:

Now for the pathwise estimator. In the score function estimator we took the gradient of
, for the pathwise estimator we will take the gradient of  . The general reasoning behind why we’d want to do it, why it helps us achieve our goal is exactly the same as stated above. That is, when we take the gradient of the regular definition of the expectation, we no longer have an expectation. However for the reason of why’d you want to use the pathwise estimator over the score function we refer you to the original article. The name “pathwise” is motivated by two equivalent ways to sample a random variant from . The first we are familiar with:
. The general reasoning behind why we’d want to do it, why it helps us achieve our goal is exactly the same as stated above. That is, when we take the gradient of the regular definition of the expectation, we no longer have an expectation. However for the reason of why’d you want to use the pathwise estimator over the score function we refer you to the original article. The name “pathwise” is motivated by two equivalent ways to sample a random variant from . The first we are familiar with: 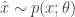 , and have used in the score function. The second and equivalent way to do this is by sampling a random variant from a simpler, continuous distribution:
, and have used in the score function. The second and equivalent way to do this is by sampling a random variant from a simpler, continuous distribution: 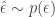 , and then transforming that variant via some function
, and then transforming that variant via some function 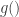 , that “encodes” the distributional parameters of the “end” distribution of interest. For a concrete example of what this means (which the authors give in the paper), say
, that “encodes” the distributional parameters of the “end” distribution of interest. For a concrete example of what this means (which the authors give in the paper), say 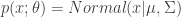 . The “path” version of sampling a random variant , is by first sampling
. The “path” version of sampling a random variant , is by first sampling 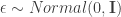 . Then we define the function :
. Then we define the function :
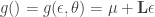 . So we have that
. So we have that  , where
, where  , and the random variant is now
, and the random variant is now 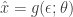 . The form of this estimator is then:
. The form of this estimator is then:
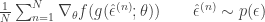
Unfortunately that’s all we’ll get into for now. Please do take a look at the original article. Thanks for checking out the lab blog and happy holidays!
