Today in lab meeting, we continued our discussion of deep unsupervised learning with a tutorial on Normalizing Flows. Similar to VAEs, which we have discussed previously, flow-based models are used to learn a generative distribution, 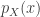 , when this is arbitrarily complex and may, for example, represent a distribution over all natural images. Alternatively, in the context of neuroscience, may represent a distribution over all possible neural population activity vectors. Learning can be useful for missing data imputation, dataset augmentation (deepfakes) or to characterize the data generating process (amongst many other applications).
, when this is arbitrarily complex and may, for example, represent a distribution over all natural images. Alternatively, in the context of neuroscience, may represent a distribution over all possible neural population activity vectors. Learning can be useful for missing data imputation, dataset augmentation (deepfakes) or to characterize the data generating process (amongst many other applications).
Flow-based models allow us to efficiently and exactly sample from , as well as to efficiently and exactly evaluate . The workhorse for Normalizing Flows is the Change of Variables formula, which maps a probability distribution over  to a simpler probability distribution, such as a multivariate Gaussian distribution, over latent variable space
to a simpler probability distribution, such as a multivariate Gaussian distribution, over latent variable space  . Assuming a bijective mapping
. Assuming a bijective mapping 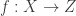 , the Change of Variables formula is
, the Change of Variables formula is
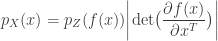
where 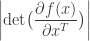 is the absolute value of the determinant of the Jacobian. This term is necessary so as to ensure probability mass is preserved during the transformation. In order to sample from , a sample from
is the absolute value of the determinant of the Jacobian. This term is necessary so as to ensure probability mass is preserved during the transformation. In order to sample from , a sample from 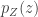 can be converted into a sample from using the inverse transformation:
can be converted into a sample from using the inverse transformation:
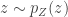
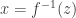
Flow-models such as NICE, RealNVP, and Glow utilize specific choices for  so as to ensure that is both invertible and differentiable (so that both sampling from and evaluating are possible), and so that the calculation of is computationally tractable (and not an
so as to ensure that is both invertible and differentiable (so that both sampling from and evaluating are possible), and so that the calculation of is computationally tractable (and not an 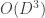 operation, where
operation, where  is the dimension of
is the dimension of  ). In lab meeting, we discussed the Coupling Layers transformation used in the RealNVP model of Dinh et al. (2017):
). In lab meeting, we discussed the Coupling Layers transformation used in the RealNVP model of Dinh et al. (2017):
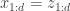
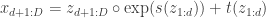
This is an invertible, differentiable mapping from latent variables 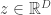 , which are sampled from a multivariate normal distribution, to the target distribution. Here ‘
, which are sampled from a multivariate normal distribution, to the target distribution. Here ‘ ‘ denotes elementwise multiplication and
‘ denotes elementwise multiplication and  and
and  are functions implemented by neural networks. The RealNVP transformation results in a triangular Jacobian with a determinant that can be efficiently evaluated as the product of the terms on the diagonal. We examined the JAX implementation of the RealNVP model provided by Eric Jang in his ICML 2019 tutorial.
are functions implemented by neural networks. The RealNVP transformation results in a triangular Jacobian with a determinant that can be efficiently evaluated as the product of the terms on the diagonal. We examined the JAX implementation of the RealNVP model provided by Eric Jang in his ICML 2019 tutorial.
As a neural computation lab, we also discussed the potential usefulness of flow-based models in a neuroscience context. Some potential limitations to their usefulness may lie in the fact that they are typically used to model continuous probability distributions; yet in neuroscience, we are often interested in Poisson-like spike distributions. However, recent work on dequantization, which describes how to model discrete pixel intensities with flows, may provide inspiration for how to handle the discreteness of neural data. One other potential limitation to their usefulness related to the fact that the dimensionality of the latent variable in flow-models is equal to that of the observed data. In neuroscience, we are often interested in finding lower-dimensional structure within neural population data; so flow-based models may not be well-suited for this purpose. Regardless of these potential limitations; it is clear that normalizing flows models are powerful and we look forward to continuing to explore their applications in the future.

