
Pitkow et al., Neuron, 87, 411-423, 2015
A couple of weeks ago I presented Xaq Pitkow et al.’s paper examining the convoluted relationship between choice probabilities (CP), information-limiting correlations (ILC), and suboptimal coding.
The paper is prefaced by two observations:
- Optimal linear decoding theory suggests that the CPs should decrease as the number of neurons in a pool increase. This can be true even if noise correlations are non-zero. This would imply that, given the enormous number of neurons that are in the brain, that CPs should be extraordinarily tiny. Yet, single neurons often exhibit significant CPs.
- Single neurons have detection thresholds that are not much greater (or can actually exceed) psychophysical thresholds. Therefore, if the animal has access to individual neurons with this sensitivity to the stimulus, then why wouldn’t pooling across many of them make behavior reflective of even lower detection thresholds?
The claim is that optimal decoding strategies can conspire with ILC to make these observations plausible under conditions observed in the brain.
In order to understand these claims, let’s define a few quantities. The linear estimate of the stimulus with respect to some reference value of the stimulus 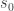
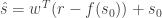
where 


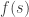
If the noise covariance matrix is given by 

where 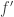


The key ingredient here is information limiting correlations (to find out what these are I would read this paper by Moreno-Bote et al. 2014). If the noise correlations display ILC then the noise covariance can be written in the form 
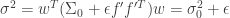


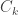
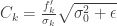
where 


The stronger prediction of the paper is also a bit harder to follow, and is a bit less intuitive, so I’ll just outline the main points. Suppose there are two populations (

It seems to me that almost any case in which the entire population is not recorded, but that has ILCs, would display this kind of behavior, so I’m not entirely sure how to interpret the claim that there is actually a non-decoded and a decoded population and that we can distinguish between them. But maybe I missed something.
The paper was a very interesting unification of ILCs, choice probabilities, and optimal linear decoding. I’m sure we’ll be seeing follow-ups from this paper.

I think there is a small typo in the efinition of w, it should be f’^T in the denominator..
Thanks for the post!
Great catch — thanks!
Thanks for the post, and for discussing my paper! I have two corrections.
1) Your formula for C_k^opt is wrong, see Eq 10: $C_k^opt = \frac{f’_k}{\sigma_k}\sqrt{\sigma_0^2+\epsilon}$.
2) You wrote that “If only x is used by the animal for decision making, but only y is recorded, then y will have choice correlations that are proportional to, but large than x.” Actually, I’d emphasize that this CAN happen, but does not ALWAYS happen. (I interpret your post as saying it always happens). Whether a non-decoded population has higher Choice Correlations or not depends on the specifics of the noise covariance. Interestingly, this strange circumstance does seem to hold for the regions we recorded.
Cheers,
-xaq
Thanks for catching that Xaq! We had a great time discussing your paper. I’ve updated the post to reflect your comments.