
This week in lab meeting, we discussed the following work:
Learning Scalable Deep Kernels with Recurrent Structure
Al-Shedivat, Wilson, Saatchi, Hu, & Xing, JMLR 2017
This paper addressed the problem of learning a regression function that maps sequences to real-valued target vectors. Formally, the sequences of inputs are vectors of measurements ![\overline{\mathbf{x}_1}=[\mathbf{x}^1]](https://s0.wp.com/latex.php?latex=%5Coverline%7B%5Cmathbf%7Bx%7D_1%7D%3D%5B%5Cmathbf%7Bx%7D%5E1%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![\overline{\mathbf{x}_2}=[\mathbf{x}^1,\mathbf{x}^2]](https://s0.wp.com/latex.php?latex=%5Coverline%7B%5Cmathbf%7Bx%7D_2%7D%3D%5B%5Cmathbf%7Bx%7D%5E1%2C%5Cmathbf%7Bx%7D%5E2%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![\overline{\mathbf{x}_n}=[\mathbf{x}^1,\mathbf{x}^2,\dots,\mathbf{x}^n]](https://s0.wp.com/latex.php?latex=%5Coverline%7B%5Cmathbf%7Bx%7D_n%7D%3D%5B%5Cmathbf%7Bx%7D%5E1%2C%5Cmathbf%7Bx%7D%5E2%2C%5Cdots%2C%5Cmathbf%7Bx%7D%5En%5D&bg=ffffff&fg=333333&s=0&c=20201002)
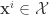



![\overline{\mathbf{x}_i}=[\mathbf{x}^{i-L+1},\mathbf{x}^{i-L+2},\dots,\mathbf{x}^i]](https://s0.wp.com/latex.php?latex=%5Coverline%7B%5Cmathbf%7Bx%7D_i%7D%3D%5B%5Cmathbf%7Bx%7D%5E%7Bi-L%2B1%7D%2C%5Cmathbf%7Bx%7D%5E%7Bi-L%2B2%7D%2C%5Cdots%2C%5Cmathbf%7Bx%7D%5Ei%5D&bg=ffffff&fg=333333&s=0&c=20201002)
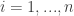

The Gaussian process (GP) is a Bayesian nonparametric model that generalizes the Gaussian distributions to functions. They assumed the mapping function 
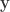

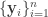
![\overline{\mathbf{x}_i}=[\mathbf{x}^{i-L+1}, \mathbf{x}^{i-L+2},\dots,\mathbf{x}^i]](https://s0.wp.com/latex.php?latex=%5Coverline%7B%5Cmathbf%7Bx%7D_i%7D%3D%5B%5Cmathbf%7Bx%7D%5E%7Bi-L%2B1%7D%2C+%5Cmathbf%7Bx%7D%5E%7Bi-L%2B2%7D%2C%5Cdots%2C%5Cmathbf%7Bx%7D%5Ei%5D&bg=ffffff&fg=333333&s=0&c=20201002)

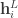

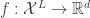


Combining the recurrent model with GP, the idea of deep kernel with recurrent model is that let 
![\{\overline{\mathbf{x}_i}=[\mathbf{x}^{i-L+1},\mathbf{x}^{i-L+2},\dots,\mathbf{x}^i]\}_{i=1}^n](https://s0.wp.com/latex.php?latex=%5C%7B%5Coverline%7B%5Cmathbf%7Bx%7D_i%7D%3D%5B%5Cmathbf%7Bx%7D%5E%7Bi-L%2B1%7D%2C%5Cmathbf%7Bx%7D%5E%7Bi-L%2B2%7D%2C%5Cdots%2C%5Cmathbf%7Bx%7D%5Ei%5D%5C%7D_%7Bi%3D1%7D%5En&bg=ffffff&fg=333333&s=0&c=20201002)
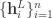

If we denote 

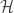
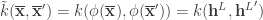
where 
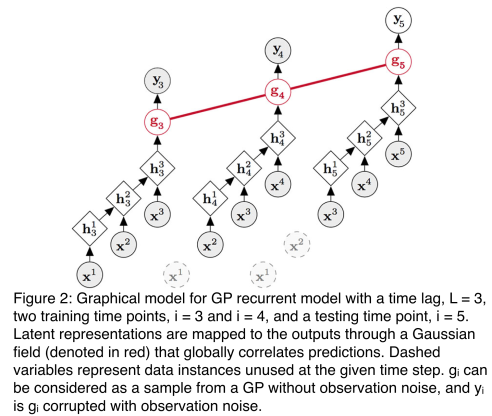
By now deep kernel with general recurrent structure has been constructed. With respect to recurrent model, there are multiple choices. Recurrent neural networks (RNNs) model recurrent processes by using linear parametric maps followed by nonlinear activations. A major disadvantage of the vanilla RNNs is that their training is nontrivial due to the so-called vanishing gradient problem: the error back-propagated through t time steps diminishes exponentially which makes learning long-term relationships nearly impossible. Thus in their paper, they chose the long short-term memory (LSTM) mechanism as the recurrent model. LSTM places a memory cell into each hidden unit and uses differentiable gating variables. The gating mechanism not only improves the flow of errors through time, but also, allows the the network to decide whether to keep, erase, or overwrite certain memorized information based on the forward flow of inputs and the backward flow of errors. This mechanism adds stability to the network’s memory. Therefore, their final model is a combination of GP and LSTM, named as GP-LSTM.
To solve the model, they needed to infer two sets of parameters: the base kernel hyperparameters, 



To evaluate their model, they applied it to a number of tasks, including system identification, energy forecasting, and self-driving car applications. Quantitatively, the model was assessed on the data ranging in size from hundreds of points to almost a million with various signal-to-noise ratios demonstrating state-of-the-art performance and linear scaling of their approach. Qualitatively, the model was tested on consequential self-driving applications: lane estimation and lead vehicle position prediction. Overall, I think this paper achieved state-of-the-art performance on consequential applications involving sequential data, following straightforward and scalable approaches to building highly flexible Gaussian process.
