A few weeks ago, Lea and Anqi co-presented a paper from Robert Datta’s group for a joint lab meeting with 3 other labs:
Mapping Sub-Second Structure in Mouse Behavior
Wiltschko, Johnson, Iurilli, Peterson, Katon, Pashkovski, Abraira, Adams, & Datta. Neuron (2015).
“It might not rival Newton’s apple, which led to his formulating the law of gravity, but the collapse of a lighting scaffold played a key role in the discovery that mice, like humans, have body language.”
Behaviors are considered to evolve according to stereotyped forms, or modules, that are arranged in sequence to enable animals to accomplish particular goals. There are some recent technical advances that facilitate more comprehensive characterization of the components of behavior, but so far these have mostly only been applied to invertebrates. For mammals, current approaches tend to rely on human observers to specify what constitutes a meaningful behavioral module. The performance of these methods is therefore limited by human perception and intuition. Given the need for automated methods for identifying (and classifying) behavior in mammals, Wiltschko et al proposed an unsupervised learning method for automatically clustering patterns of mouse behavior without human supervision. They used state-of-the-art machine-learning algorithms to systematically describe short time-scale structure of behavior in mice and to understand how the brain might alter this structure to facilitate adaptive behaviors in response to environmental changes.
In order to investigate this, Wiltschko et al collected three-dimensional depth imaging data of freely behaving mice. They first developed a number of model-free approaches to see whether there exists block-wise structure in the data, hinting at a potential organization of behavior into stereotyped modules, while also giving insight into the time-scales at which these modules are organized. Surprisingly, block-wise structure was already apparent by visual inspection alone. A change-point analysis revealed that the mean block duration was about 350 ms, in accordance with a temporal autocorrelation analysis and also roughly matching the timescale of the blocks apparent upon visual inspection. The authors also carried out a PCA analysis to show that these segmented components are sub-second blocks of behaviors that encode recognizable actions, and thus serve as stereotyped and reused behavioral modules.
After pre-processing and dimensionality reduction of the imaging data, the authors investigated a series of models aiming to discover modular structure in mouse behavior, using the model-free analysis to inform certain choices of hyper-parameters. The pipeline for the data preprocessing, dimensional compression, PCA component extraction and model fitting is shown below.

The final model that the authors used in the paper is the AR-HMM. As the name suggests, the AR-HMM combines an autoregressive (AR) model with a Hidden Markov Model (HMM). The basic idea is to model behavioral modules as a discrete hidden state, with Markovian state transitions between modules at each time point. Depending on the current behavior (i.e the value of the hidden state) the mouse’s pose evolves according to module-specific autoregressive dynamics. Once the behavioral module switches (e.g. the mouse stops walking and pauses) the dynamics that govern the evolution of the mouse’s pose also switch. Thus, each behavioral module is associated with module-specific AR dynamics and the model can be viewed as a dynamic mixture model. This can hence capture the smooth evolution of the mouse’s pose through PC space during the same behavioral epoch, but can also account for abrupt changes in pose dynamics due to changes in behavior via the latent switching state.
The final AR-HMM model that the authors use is non-parametric, allowing them to remain agnostic about the number of behavioral modules that can be identified. This HDP AR-HMM model has previously been developed in [EEMA08, EMEA09, EEMA09]. The generative model is of the form: where the Matrix Normal Inverse-Wishart (MNIW) prior is shared across the different sets of model parameters. A graphical model of the AR-HMM is shown in Figure 1 (not including parameters and priors for simplicity).
where the Matrix Normal Inverse-Wishart (MNIW) prior is shared across the different sets of model parameters. A graphical model of the AR-HMM is shown in Figure 1 (not including parameters and priors for simplicity).
 The HDP AR-HMM still requires specifying certain hyperparameters that will likely affect important characteristics of the fitted model. Most notably, the stickiness parameter
The HDP AR-HMM still requires specifying certain hyperparameters that will likely affect important characteristics of the fitted model. Most notably, the stickiness parameter  dictates how long the model will remain in a given state by affecting the probability of self-transitioning. Furthermore, the concentration parameter
dictates how long the model will remain in a given state by affecting the probability of self-transitioning. Furthermore, the concentration parameter  determines the spread of the DP and thus affects the number of motifs the model will identify. While a non-informative prior is put over , is set using the previous change-point analysis, essentially tuning the model to the time-scale of interest. In order to determine the relevant number of time-lags in the AR-component of the model, the authors placed a block ARD prior over
determines the spread of the DP and thus affects the number of motifs the model will identify. While a non-informative prior is put over , is set using the previous change-point analysis, essentially tuning the model to the time-scale of interest. In order to determine the relevant number of time-lags in the AR-component of the model, the authors placed a block ARD prior over  . Finally, inference in the HDP AR-HMM was carried out via Gibbs Sampling.
. Finally, inference in the HDP AR-HMM was carried out via Gibbs Sampling.
The HDP AR-HMM is a powerful and flexible modeling framework for identifying behavioral modules in mice and relates closely to a larger body of work on switching time-series models with Markovian structure (Jump-Markov models, Switching Linear Dynamical Systems). These models have been applied to problems ranging from speech recognition [BD07] to neural data analysis [BMJGSKM11], illustrating their flexibility and expressive power.
To demonstrate the advantages of using the AR-HMM compared to previous supervised approaches, the authors first characterized baseline patterns of behavior when the mouse is freely moving in a circular open field. They found that the model manages to group stereotyped behaviors (like e.g. a low rear or a left turn) in the same cluster and can identify meaningful modules that are representative of normal mouse exploratory behaviors in the laboratory — all in an entirely unsupervised fashion.
Next, the authors utilized the AR-HMM model to gain insight into the nature of behavioral changes that may arise due to changes in the environment. First, they changed the circular field to a square arena and discovered that a small number of behavioral modules are uniquely expressed in only the circular or the square arena, while other modules are expressed more or less frequently in one or the other arena. Second, the authors delivered an aversive fox odor to a quadrant of the square arena, which is known to lead to profound changes in mouse behavior characterized by odor investigation, escape, and freezing. The AR-HMM analysis revealed that the seemingly new behaviors were best described by up- or down-regulating modules that were identified previously during normal behavior, together with an altered transition structure between the individual modules. Thus, the behavioral changes associated with the aversive odor are not due to the introduction of new behavioral modules but are rather regulated via a re-arrangement of the components of normal behavior.
Finally, the authors investigated how genetic mutations and manipulations of neural activity may influence the sub-second structure of mouse behavior. They first characterized the phenotype of mice carrying a homozygous or heterozygous genetic mutation using the AR-HMM model framework. While the homozygous mutation results in an abnormal waddling walk, no phenotype has previously been reported for the heterozygous mutation, in which mice only have one copy of the mutated gene. The AR-HMM model correctly identifies a behavioral module unique to the homozygous mutants representing the waddling gate, but also shows that other behavioral modules are up-regulated in these mutants. Furthermore, the analysis revealed that the heterozygous mice do have a phenotype that distinguished them from wild type mice: they over-express the same set of modules that were up-regulated in the homozygous mutants, while failing to express the module for waddling gait. Thus, the AR-HMM allows one to gain insight into subtle behavioral differences that were not previously identifiable by human observers. The authors next investigate the effects of manipulating neural activity by optical stimulation using unilaterally expressed Channelrhodopsin-2 in a subset of layer 5 corticostriatal neurons in motor cortex. AR-HMM identifies and characterizes both obvious and subtle optogenetically induced phenotypes, distinguishing “new” optogenetically induced behaviors from up-regulated expression of “old” behaviors.
Overall, we think that unsupervised probabilistic machine learning is an interesting approach to better understanding the architecture of mouse behavior. Using a generative modeling approach provides a principled framework for investigating questions relating not only to the organization of behavior at fine time scales, but also to the influence of environmental factors, individual genes or neural circuits on mouse behavior. All in all, this work may facilitate a better fundamental understanding of how the brain can build and adapt patterns of behavior and may also have interesting implications for diagnosing disease based on subtle behavioral phenotypes.
References:
[EEMA08] Emily B Fox, Erik B Sudderth, Michael I Jordan, and Alan S Willsky. An hdp-hmm for systems with state persistence. In Proceedings of the 25th international conference on Machine learning, pages 312–319. ACM, 2008.
[EMEA09] Emily Fox, Michael I Jordan, Erik B Sudderth, and Alan S Willsky. Sharing features among dynamical systems with beta processes. In Advances in Neural Information Processing Systems, pages 549–557, 2009.
[EEMA09] Emily Fox, Erik Sudderth, Michael Jordan, and A Willsky. Nonparametric bayesian identification of jump systems with sparse dependencies. In Proc. 15th IFAC Sympo- sium on System Identification, pages 1886–1898, 2009.
[BD07] Bertrand Mesot and David Barber. Switching linear dynamical systems for noise ro- bust speech recognition. Audio, Speech, and Language Processing, IEEE Transactions on, 15(6):1850–1858, 2007.
[BMJGSKM11] Biljana Petreska, M Yu Byron, John P Cunningham, Gopal Santhanam, Stephen I Ryu, Krishna V Shenoy, and Maneesh Sahani. Dynamical segmentation of single trials from population neural data. In Advances in neural information processing systems, pages 756–764, 2011.

![\overline{\mathbf{x}_1}=[\mathbf{x}^1]](https://s0.wp.com/latex.php?latex=%5Coverline%7B%5Cmathbf%7Bx%7D_1%7D%3D%5B%5Cmathbf%7Bx%7D%5E1%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![\overline{\mathbf{x}_2}=[\mathbf{x}^1,\mathbf{x}^2]](https://s0.wp.com/latex.php?latex=%5Coverline%7B%5Cmathbf%7Bx%7D_2%7D%3D%5B%5Cmathbf%7Bx%7D%5E1%2C%5Cmathbf%7Bx%7D%5E2%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![\overline{\mathbf{x}_n}=[\mathbf{x}^1,\mathbf{x}^2,\dots,\mathbf{x}^n]](https://s0.wp.com/latex.php?latex=%5Coverline%7B%5Cmathbf%7Bx%7D_n%7D%3D%5B%5Cmathbf%7Bx%7D%5E1%2C%5Cmathbf%7Bx%7D%5E2%2C%5Cdots%2C%5Cmathbf%7Bx%7D%5En%5D&bg=ffffff&fg=333333&s=0&c=20201002)
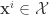



![\overline{\mathbf{x}_i}=[\mathbf{x}^{i-L+1},\mathbf{x}^{i-L+2},\dots,\mathbf{x}^i]](https://s0.wp.com/latex.php?latex=%5Coverline%7B%5Cmathbf%7Bx%7D_i%7D%3D%5B%5Cmathbf%7Bx%7D%5E%7Bi-L%2B1%7D%2C%5Cmathbf%7Bx%7D%5E%7Bi-L%2B2%7D%2C%5Cdots%2C%5Cmathbf%7Bx%7D%5Ei%5D&bg=ffffff&fg=333333&s=0&c=20201002)
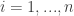


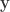

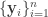
![\overline{\mathbf{x}_i}=[\mathbf{x}^{i-L+1}, \mathbf{x}^{i-L+2},\dots,\mathbf{x}^i]](https://s0.wp.com/latex.php?latex=%5Coverline%7B%5Cmathbf%7Bx%7D_i%7D%3D%5B%5Cmathbf%7Bx%7D%5E%7Bi-L%2B1%7D%2C+%5Cmathbf%7Bx%7D%5E%7Bi-L%2B2%7D%2C%5Cdots%2C%5Cmathbf%7Bx%7D%5Ei%5D&bg=ffffff&fg=333333&s=0&c=20201002)

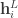

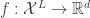



![\{\overline{\mathbf{x}_i}=[\mathbf{x}^{i-L+1},\mathbf{x}^{i-L+2},\dots,\mathbf{x}^i]\}_{i=1}^n](https://s0.wp.com/latex.php?latex=%5C%7B%5Coverline%7B%5Cmathbf%7Bx%7D_i%7D%3D%5B%5Cmathbf%7Bx%7D%5E%7Bi-L%2B1%7D%2C%5Cmathbf%7Bx%7D%5E%7Bi-L%2B2%7D%2C%5Cdots%2C%5Cmathbf%7Bx%7D%5Ei%5D%5C%7D_%7Bi%3D1%7D%5En&bg=ffffff&fg=333333&s=0&c=20201002)
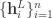



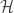
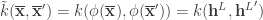





 consisting of
consisting of  i.i.d. samples of some continuous or discrete variable
i.i.d. samples of some continuous or discrete variable 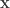 .
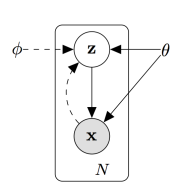
.  is an unobserved continuous random variable generating the data (solid lines:
is an unobserved continuous random variable generating the data (solid lines:  ), where
), where  is the parameter set involved in the generative model. The ultimate task is to learn both
is the parameter set involved in the generative model. The ultimate task is to learn both 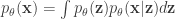 , and maximize this likelihood to learn
, and maximize this likelihood to learn  : an approximation to the intractable true posterior
: an approximation to the intractable true posterior 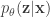 , which is interpreted as a probabilistic encoder (dash line in the directed graph), and correspondingly,
, which is interpreted as a probabilistic encoder (dash line in the directed graph), and correspondingly, 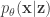 is the probabilistic decoder. Given the recognition model, the variational lower bound
is the probabilistic decoder. Given the recognition model, the variational lower bound 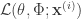 is defined as
is defined as![\mbox{log}p_\mathbf{\theta}(\mathbf{x}^{(i)})\ge\mathcal{L}(\mathbf{\theta},\Phi;\mathbf{x}^{(i)})=-D_{KL}(q_\Phi(\mathbf{z}|\mathbf{x}^{(i)})||p_\mathbf{\theta}(\mathbf{z}))+\mathbb{E}_{q_\Phi(\mathbf{z}|\mathbf{x}^{(i)})}\left[\mbox{log}p_\mathbf{\theta}(\mathbf{x}^{(i)}|\mathbf{z})\right]](https://s0.wp.com/latex.php?latex=%5Cmbox%7Blog%7Dp_%5Cmathbf%7B%5Ctheta%7D%28%5Cmathbf%7Bx%7D%5E%7B%28i%29%7D%29%5Cge%5Cmathcal%7BL%7D%28%5Cmathbf%7B%5Ctheta%7D%2C%5CPhi%3B%5Cmathbf%7Bx%7D%5E%7B%28i%29%7D%29%3D-D_%7BKL%7D%28q_%5CPhi%28%5Cmathbf%7Bz%7D%7C%5Cmathbf%7Bx%7D%5E%7B%28i%29%7D%29%7C%7Cp_%5Cmathbf%7B%5Ctheta%7D%28%5Cmathbf%7Bz%7D%29%29%2B%5Cmathbb%7BE%7D_%7Bq_%5CPhi%28%5Cmathbf%7Bz%7D%7C%5Cmathbf%7Bx%7D%5E%7B%28i%29%7D%29%7D%5Cleft%5B%5Cmbox%7Blog%7Dp_%5Cmathbf%7B%5Ctheta%7D%28%5Cmathbf%7Bx%7D%5E%7B%28i%29%7D%7C%5Cmathbf%7Bz%7D%29%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002)
 ,
, 
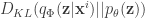 has an analytical form. The major tricky term is the expectation which usually doesn’t have any closed solution. The usual Monte Carlo estimator for this type of problem exhibits very high variance and is not capable to take derivatives w.r.t.
has an analytical form. The major tricky term is the expectation which usually doesn’t have any closed solution. The usual Monte Carlo estimator for this type of problem exhibits very high variance and is not capable to take derivatives w.r.t. 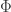 . Given such a problem, the paper proposed a reparameterization trick of the expectation term yields a lower bound estimator that can be straightforwardly optimized using standard stochastic gradient methods.
. Given such a problem, the paper proposed a reparameterization trick of the expectation term yields a lower bound estimator that can be straightforwardly optimized using standard stochastic gradient methods. in two steps:
in two steps: (random seed independent of
(random seed independent of 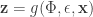 (differentiable perturbation)
(differentiable perturbation)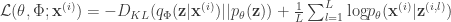
 and
and 
