
On July 28th, I presented the following paper in lab meeting:
- Efficient and direct estimation of a neural subunit model for sensory coding,
Vintch, Zaharia, Movshon, & Simoncelli, NIPS 2012
This paper proposes a new method for characterizing the multi-dimensional stimulus selectivity of sensory neurons. The main idea is that, instead of thinking of neurons as projecting high-dimensional stimuli into an arbitrary low-dimensional feature space (the view underlying characterization methods like STA, STC, iSTAC, GQM, MID, and all their rosy-cheeked cousins), it might be more useful / parsimonious to think of neurons as performing a projection onto convolutional subunits. That is, rather than characterizing stimulus selectivity in terms of a bank of arbitrary linear filters, it might be better to consider a subspace defined by translated copies of a single linear filter.
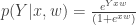 , where Y is the observer’s responses, x is a matrix of the stimulus (trials x stimulus vector) augmented by a column of ones (for the observer’s bias), and w is the observer’s kernel (size = [1 x(1,:)]). Using a sparse prior (L1 norm) over a set of smooth basis (defined by a
, where Y is the observer’s responses, x is a matrix of the stimulus (trials x stimulus vector) augmented by a column of ones (for the observer’s bias), and w is the observer’s kernel (size = [1 x(1,:)]). Using a sparse prior (L1 norm) over a set of smooth basis (defined by a 