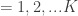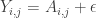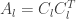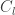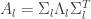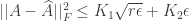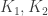This week in computational neuroscience journal club we discussed the paper
Neuronal Circuits Underlying Persistent Representations Despite Time Varying Activity
Shaul Druckmann and Dmitri B. Chklovskii
Current Biology, 22(22):2095–2103, 2012.
The main idea of this work was to demonstrate that the fact that non-trivial temporal dynamics occur in neural circuits, this activity does not prevent such circuits from persistently representing a constant stimulus. The main example used (although other neural regions, such as V1 are discussed) is working memory in pre-frontal cortex. The authors cite previous literature that has shown that even when a stimulus is `stored’ in memory, there is still significant time-varying neural activity. While the authors make no indication that the represented stimulus must be preserved (i.e. temporal dynamics are due to temporally changing stimulus representations), they do present a viable architecture that describes how the temporal dynamics do not effect the stimulus stored for the working memory task.
At a high level, the authors use the high redundancy of neural circuits to introduce a network that can retain a stimulus in the space of allowable features while still permitting neural activity to continue changing the null-space of the feature matrix. This paper ties together some very nice concepts from linear algebra and network dynamics to present a nice and tidy `proof-by-construction’ of the hypothesis that evolving networks can retain constant stimuli information. To tie this paper in a broader setting, the network dynamics here are similar to those used in network encoding models (e.g. the locally competitive algorithm for sparse coding) and the idea of non-trivial activity in the null space of a neural representation ties in nicely to later work discussing preparatory activity in motion tasks.
The formal mathematics of the paper are concerned with neural representations based on the linear generative model. This model asserts that a stimulus  can be composed of a linear sum of $K$ dictionary elements
can be composed of a linear sum of $K$ dictionary elements 
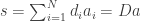
where the coefficients  represent amount of each
represent amount of each 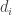 needed to construct
needed to construct  . In the network, is also the activity of neuron
. In the network, is also the activity of neuron  , meaning that activity in neuron directly relates to the stimulus encoded by the network. If the number of dictionary elements
, meaning that activity in neuron directly relates to the stimulus encoded by the network. If the number of dictionary elements  is the same as the dimension of the stimulus
is the same as the dimension of the stimulus  , then there is no possible way for the neural activity
, then there is no possible way for the neural activity  to deviate from the unique solution
to deviate from the unique solution  without changing the stimulus encoded by the system. The authors note, however, that in many neural systems, the neural code is highly redundant (i.e.
without changing the stimulus encoded by the system. The authors note, however, that in many neural systems, the neural code is highly redundant (i.e. 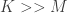 ), indicating that the matrix
), indicating that the matrix  has a large null-space and thus there are an infinite number of ways that can change while still faithfully encoding the stimulus.
has a large null-space and thus there are an infinite number of ways that can change while still faithfully encoding the stimulus.
With the idea of allowing neural activity to vary within the nullspace, the authors turn to an analysis of a specific neural network evolution equation where the change in neural activity decays is defined by a leaky-integrator-type system

where  is the network time constant, and
is the network time constant, and  is the network connectivity matrix, i.e.
is the network connectivity matrix, i.e. 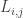 indicates how activity in neuron
indicates how activity in neuron  influences neuron . The authors do not specify a particular input method, however it seems that it is assumed that at
influences neuron . The authors do not specify a particular input method, however it seems that it is assumed that at 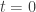 the neural activity encodes the stimulus. To keep the stimulus constant, the authors observe that setting
the neural activity encodes the stimulus. To keep the stimulus constant, the authors observe that setting

results in the feature vector recombination (FEVER) rule
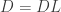
This rule is the primary focus of attention of the paper. The FEVER rule is a mathematically simple rule that lays out the necessary condition for a linear network (and some classes of non-linear networks) to have time-varying activity while encoding the same stimulus. Note that this concept is in stark contrast to much of the encoding literature (particularly for vision) which utilizes over-complete neural codes to encode stimuli more efficiently. Instead this work does not try to constrain the encoding any more than the encoding must represent the stimulus. The remainder of this paper is concerned with how such networks can be found given a feature dictionary and the resulting properties of the connectivity matrix . Specifically the problem of finding given is highly under-determined. In fact there are  unknowns and only equations. As we already have
unknowns and only equations. As we already have 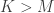 , this problem requires fairly strong regularization in order to yield a good solution. Two methods are proposed to solve for . The first method seeks a sparse connectivity matrix by solving the
, this problem requires fairly strong regularization in order to yield a good solution. Two methods are proposed to solve for . The first method seeks a sparse connectivity matrix by solving the  -regularized least squares (LASSO) optimization
-regularized least squares (LASSO) optimization
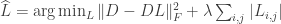
where  trades off between the sparsity of and how strictly we adhere to the FEVER rule. This optimization, however, could result in neurons that both excite and inhibit other neurons. By Dale’s law, this should not be possible, so an alternate optimization is proposed. Setting
trades off between the sparsity of and how strictly we adhere to the FEVER rule. This optimization, however, could result in neurons that both excite and inhibit other neurons. By Dale’s law, this should not be possible, so an alternate optimization is proposed. Setting  where
where  is an excitatory matrix and
is an excitatory matrix and  is an inhibition matrix, the authors make the assumption that there are dispersed, yet sparse excitation connections ( is sparse) and that there are few, widely connected, inhibitory neurons ( is low-rank). Thus these two matrices can be solved using a “sparse + low-rank” optimization program
is an inhibition matrix, the authors make the assumption that there are dispersed, yet sparse excitation connections ( is sparse) and that there are few, widely connected, inhibitory neurons ( is low-rank). Thus these two matrices can be solved using a “sparse + low-rank” optimization program
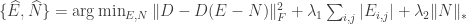
where  trade off between the sparsity of , rank of and adherence to the FEVER rule. This optimization is surprisingly well defined and allows for the determination of from . Before implementing this learning, however, the authors note two more aspects of the model. First, by using a modified FEVER rule
trade off between the sparsity of , rank of and adherence to the FEVER rule. This optimization is surprisingly well defined and allows for the determination of from . Before implementing this learning, however, the authors note two more aspects of the model. First, by using a modified FEVER rule  , a memory element can be built into the network. Second, certain classes of nonlinear networks can use the FEVER rule to preserve stimulus encoding. Specifically, networks that evolve as
, a memory element can be built into the network. Second, certain classes of nonlinear networks can use the FEVER rule to preserve stimulus encoding. Specifically, networks that evolve as

with a point-wise nonlinearity 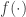 will have
will have 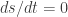 for a linear generative model. This property only holds, however, since the nonlinearity comes before the linear summation . If the nonlinearity came afterwards, the derivative of would have to be accounted for, complicating the calculations. The authors use these two properties to introduce realistic properties, such as fading memory and spiking activity, into the FEVER network.
for a linear generative model. This property only holds, however, since the nonlinearity comes before the linear summation . If the nonlinearity came afterwards, the derivative of would have to be accounted for, complicating the calculations. The authors use these two properties to introduce realistic properties, such as fading memory and spiking activity, into the FEVER network.
With the network architecture set and an inference method for , the authors then analyze the resulting properties of the connectivity . Specifically, the authors make note of the eigenvalues and engenvectors as well as the occurrence of different motifs (connectivity patters). The authors also make indirect observations by looking at the resulting time-traces resulting from the dynamics under the FEVER network.
In terms of the eigenvalues – arguably the most important aspect of a linear dynamical system – the first major observation is that must have at least eigenvalues at one. This necessitates from the fact that in the FEVER condition, must preserve all the stimulus dimensions. As all other eigenvalues lie in the null-space of , the authors do not prove stability directly, but instead demonstrate empirically that the FEVER networks do not result in large eigenvalues. It most likely helps that sparsity constraints attempt to reduce the overall magnitude of the network connections, reducing the chance that eigenvalues not necessary for maintaining the stimulus will be bias towards smaller values (more explicitly so in the low-rank segment of the Dale’s FEVER inference). As a side note, the authors do present, however, in the supplementary information a proof that inhibitory connections are required for stability.
For the eigenvectors, the authors mostly aim to show that there are mostly sparse connections between neurons (i.e. FEVER networks are not fully connected). Branching from this measure, the total number of single connections, pairs of connected neurons, and motifs of triads of connected neurons are compared to the similar counts in rat V1, layer V. The authors show that the above-chance occurrence of these connectivity patters match the above-chance occurrences in rat V1.
For the indirect relation to biological systems, the authors also show how the temporal evolution in time can match the behavior of pre-frontal cortex in working memory tasks. Specifically, a spiking FEVER network is driven to a given stimulus, and then allowed to evolve naturally. The authors observe that the PSTH of subsets of neurons match the qualitative behaviors observed in biological studies: ramp up, ramp down, and time-invariant.
The authors use this accumulation of evidence to as a steps to the conclusion that time-varying activity and persistent stimulus encoding are not mutually exclusive. All in all I believe the following quote from the paper summarizes the paper quite nicely:
“Our study does not refute the idea of explicit coding of time in working memory but rather shows that time-varying activity does not necessarily imply that the underlying network stimulus representations explicitly encodes time-varying properties”