After a nearly 1-year hiatus, we’ve restarted our reading group on non-parametric (NP) Bayesian methods, focused on models for discrete data based on generalizations of the Dirichlet and other stick-breaking processes.
Thursday (9/20) was our first meeting, and Karin led a discussion of:
Teh, Y. W. (2006). A hierarchical Bayesian language model based on Pitman-Yor
processes. Proceedings of the 21st International Conference on
Computational Linguistics and the 44th annual meeting of the
Association for Computational Linguistics. 985-992
In the first meeting, we made it only as far as describing the Pitman-Yor (PY) process, a stochastic process whose samples are random probability distributions, and two methods for sampling from it:
- Chinese Restaurant sampling (aka “Blackwell-MacQueen urn scheme”), which directly provides samples
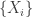 from distribution
from distribution 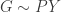 with G marginalized out.
with G marginalized out.
- Stick-breaking, which samples the distribution
 explicitly, using iid draws of Beta random variables to obtain stick weights
explicitly, using iid draws of Beta random variables to obtain stick weights 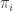 .
.
We briefly discussed the intuition for the hierarchical PY process, which uses PY process as base measure for PY process priors at deeper levels of the hierarchy (applied here to develop an n-gram model for natural language).
Next week: We’ve decided to go a bit further back in time to read:
Teh, Y. W.; Jordan, M. I.; Beal, M. J. & Blei, D. M. (2006). Hierarchical dirichlet processes. Journal of the American Statistical Association 101:1566-1581.
Time: Thursday (9/27), 4:00pm.
Location: Pillow lab
Presenter: Karin
note: if you’d like to be added to the email announcement list for this group, please send email to pillow AT mail.utexas.edu.

 (“global measure” sampled from DP with base measure
(“global measure” sampled from DP with base measure  and concentration
and concentration  ).
). (sequence of conditionally independent random measures with common base measure
(sequence of conditionally independent random measures with common base measure  , e.g.,
, e.g., 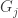 are distributions over clusters from data collected on different days)
are distributions over clusters from data collected on different days)