Today I presented a paper from Liam’s group: “A new look at state-space models for neural data”, Paninski et al, JCNS 2009
The paper presents a high-level overview of state-space models for neural data, with an emphasis on statistical inference methods. The basic setup of these models is the following:
• Latent variable  defined by dynamics distribution:
defined by dynamics distribution: 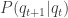
• Observed variable  defined by observation distribution:
defined by observation distribution:  .
.
These two ingredients ensure that the joint probability of latents and observed variables is
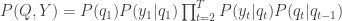 .
.
A variety of applications are illustrated (e.g., = common input noise; = multi-neuron spike trains).
The two problems we’re interested in solving, in general, are:
(1) Filtering / Smoothing: inferring from noisy observations , given the model parameters  .
.
(2) Parameter Fitting: inferring from observations .
The “standard” approach to these problems involves: (1) recursive approximate inference methods that involve updating a Gaussian approximation to  using its first two moments; and (2) Expectation-Maximization (EM) for inferring . By contrast, this paper emphasizes: (1) exact maximization for , which is tractable in
using its first two moments; and (2) Expectation-Maximization (EM) for inferring . By contrast, this paper emphasizes: (1) exact maximization for , which is tractable in  via Newton’s Method, due to the banded nature of the Hessian; and (2) direct inference for using the Laplace approximation to
via Newton’s Method, due to the banded nature of the Hessian; and (2) direct inference for using the Laplace approximation to 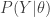 . When the dynamics are linear and the noise is Gaussian, the two methods are exactly the same (since a Gaussian’s maximum is the same as its mean; the forward and backward recursions in Kalman Filtering/Smoothing are the same set of operations needed by Newton’s method). But for non-Gaussian noise or non-linear dynamics, the latter method may (the paper argues) provide much more accurate answers with approximately the same computational cost.
. When the dynamics are linear and the noise is Gaussian, the two methods are exactly the same (since a Gaussian’s maximum is the same as its mean; the forward and backward recursions in Kalman Filtering/Smoothing are the same set of operations needed by Newton’s method). But for non-Gaussian noise or non-linear dynamics, the latter method may (the paper argues) provide much more accurate answers with approximately the same computational cost.
Key ideas of the paper are:
- exact maximization of a log-concave posterior
- computational cost, due to sparse (tridiagonal or banded) Hessian.
- the Laplace approximation (Gaussian approximation to the posterior using its maximum and second-derivative matrix), which is (more likely to be) justified for log-concave posteriors
- log-boundary method for constrained problems (which preserves sparsity)
Next week: we’ll do a basic tutorial on Kalman Filtering / Smoothing (and perhaps, EM).

