Optimal tuning curve is the best transformation of the stimulus into neural firing pattern (usually firing rate) under certain constraints and optimality criterion. The following paper I saw at NIPS 2012 was related to what we are doing, so we took a deeper look into it.
Wang, Stocker & Lee (NIPS 2012), Optimal neural tuning curves for arbitrary stimulus distributions: Discrimax, infomax and minimum Lp loss.
The paper assumes a single neuron encoding a 1 dimensional stimulus, governed by a distribution 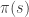 . The neuron is assumed to be Poisson (pure rate code). The neuron’s tuning curve
. The neuron is assumed to be Poisson (pure rate code). The neuron’s tuning curve  is smooth, monotonically increasing (with
is smooth, monotonically increasing (with  ), and has a limited minimum and maximum firing rate as its constraint. Authors assume asymptotic regime for MLE decoding where the observation time
), and has a limited minimum and maximum firing rate as its constraint. Authors assume asymptotic regime for MLE decoding where the observation time  is long enough to apply asymptotic normality theory (and convergence of p-th moments) of MLE.
is long enough to apply asymptotic normality theory (and convergence of p-th moments) of MLE.
The authors show that there is a 1-to-1 mapping between the tuning curve and the Fisher information  under these constraints. Then for various loss functions, they derive the optimal tuning curve using calculus of variations. In general, to minimize the Lp loss
under these constraints. Then for various loss functions, they derive the optimal tuning curve using calculus of variations. In general, to minimize the Lp loss ![E\left[ |\hat s - s|^p \right]](https://s0.wp.com/latex.php?latex=E%5Cleft%5B+%7C%5Chat+s+-+s%7C%5Ep+%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002) under the constraints, the optimal (squared) tuning curve is:
under the constraints, the optimal (squared) tuning curve is:

Furthermore, in the limit of 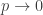 , the optimal solution corresponds to the infomax solution (i.e., optimum for mutual information loss). However, all the analysis is only in the asymptotic limit, where the Cramer-Rao bound is attained by the MLE. For the case of mutual information, unlike noise-less case where the optimal tuning curve becomes the stimulus CDF (Laughlin), for Poisson noise, it turns out to be the square of the stimulus CDF. I have plotted the differences below for a normal distribution (left) and a mixture of normals (right):
, the optimal solution corresponds to the infomax solution (i.e., optimum for mutual information loss). However, all the analysis is only in the asymptotic limit, where the Cramer-Rao bound is attained by the MLE. For the case of mutual information, unlike noise-less case where the optimal tuning curve becomes the stimulus CDF (Laughlin), for Poisson noise, it turns out to be the square of the stimulus CDF. I have plotted the differences below for a normal distribution (left) and a mixture of normals (right):

The results are very nice, and I’d like to see more results with stimulus noise and with population tuning assumptions.


