
We recently read oi-VAE: Output Interpretable VAEs for Nonlinear Group Factor Analysis, which was published at ICML in 2018 by Samuel Ainsworth, Nicholas Foti, Adrian Lee, and Emily Fox. This paper proposes a nonlinear group factor analysis model that is an adaptation of VAEs to data with groups of observations. The goal is to identify nonlinear relationships between groups and to learn latent dimensions that control nonlinear interactions between groups. This encourages disentangled latent representations among sets of functional groups. A prominent example in the paper is motion capture data, where we desire a generative model of human walking and train on groups of observed recorded joint angles.
Let us consider observations 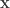

![\mathbf{x} = [\mathbf{x}^{(1)}, \cdots, \mathbf{x}^{(G)}]](https://s0.wp.com/latex.php?latex=%5Cmathbf%7Bx%7D+%3D+%5B%5Cmathbf%7Bx%7D%5E%7B%281%29%7D%2C+%5Ccdots%2C+%5Cmathbf%7Bx%7D%5E%7B%28G%29%7D%5D&bg=ffffff&fg=333333&s=0&c=20201002)
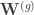
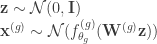
for each 

oi-VAE generative model (Ainsworth et al., 2018)
For learning interpretable sets of latents that control separate groups, the key feature of this approach is to place a sparsity-inducing prior on the columns of each
The model is trained in the standard VAE approach by optimizing the ELBO with an amortized inference network 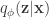
![\mathcal{L}(\phi, \theta, \mathcal{W}) = \mathbb{E}_{q_\phi(\mathbf{z} | \mathbf{x})} [ \log p(\mathbf{x} | \mathbf{z}, \mathcal{W}, \theta)] - D_{\mathrm{KL}} ( q_\phi(\mathbf{z} | \mathbf{x}) || p(\mathbf{z}) ) + \log p(\theta) - \lambda \sum_{g,j} \| w_j^{(g)} \|_2](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BL%7D%28%5Cphi%2C+%5Ctheta%2C+%5Cmathcal%7BW%7D%29+%3D+%5Cmathbb%7BE%7D_%7Bq_%5Cphi%28%5Cmathbf%7Bz%7D+%7C+%5Cmathbf%7Bx%7D%29%7D+%5B+%5Clog+p%28%5Cmathbf%7Bx%7D+%7C+%5Cmathbf%7Bz%7D%2C+%5Cmathcal%7BW%7D%2C+%5Ctheta%29%5D+-+D_%7B%5Cmathrm%7BKL%7D%7D+%28+q_%5Cphi%28%5Cmathbf%7Bz%7D+%7C+%5Cmathbf%7Bx%7D%29%C2%A0+%7C%7C+p%28%5Cmathbf%7Bz%7D%29+%29+%2B+%5Clog+p%28%5Ctheta%29+-+%5Clambda+%5Csum_%7Bg%2Cj%7D+%5C%7C+w_j%5E%7B%28g%29%7D+%5C%7C_2&bg=ffffff&fg=333333&s=0&c=20201002)
where 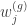


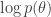
The above objective consists of a differentiable term (the ELBO plus log prior on 
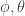
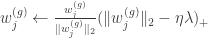
to each 
The authors validate the approach on a toy example. They generated synthetic bars data, where one row of a square matrix was sampled from a Gaussian with non-zero mean while the rest of the matrix was sampled from zero-mean noise. The authors fit oi-VAE with each group set to a row of observations, and found that the model learned the appropriate sparse mapping where each latent component mapped to one of the rows. This latent space improved on the VAE, which did not have any discernible structure in the latent space. Importantly, oi-VAE still successfully identified the correct number of latent components (8) and sparse mapping even when the model was fit with double the amount of components.

(a) Synthetic bar data example and (b) reconstruction from oi-VAE. The learned oi-VAE latent-group mappings (c) match the true structure, while a VAE (d) does not learn a sparse structure.
After validating the approach, the authors applied it to motion capture data. Here, the output groups were different joint angles. They trained the oi-VAE model on walking motion capture data. The learned latent dimensions nicely corresponded to intuitive groups of joint angles, such as the left leg (left foot, left lower leg, left upper leg). Next, the imposed structure in the model helped it generate more realistic unconditional samples of walking than the VAE, presumably because the inductive bias allowed oi-VAE to better learn invalid joint angles.

Unconditional walking pose samples from the VAE and oi-VAE models.
These results suggest the oi-VAE is a useful model for discovering nonlinear interactions between groups. In particular, I liked the approach of adding structure in the generative model to gain interpretability, and hypothesize that adding other forms of structure to VAE generative models is a good way to encourage disentangled representations (see a recent example of this in Dieng et al., 2019).
Two questions when using the approach are how to choose
