
This week we discussed a recent paper from Anne Churchland and colleagues:
Variance as a Signature of Neural Computations during Decision Making,
Anne. K. Churchland, R. Kiani, R. Chaudhuri, Xiao-Jing Wang, Alexandre Pouget, & M.N. Shadlen. Neuron, 69:4 818-831 (2011).
This paper examines the variance of spike counts in area LIP during the “random dots” decision-making task. While much has been made of (trial-averaged) spike rates in these neurons (specifically, the tendency to “ramp” linearly during decision-making), little has been made of their variability.
The paper’s central goal is to divide the net spike count variance (measured in 60ms bins) into two fundamental components, in accordance with a doubly stochastic modulated renewal model of the response. We can formalize this as follows: let 
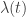

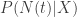
– the distribution over rate given the task variables. This is the primary object of interest;
is the “desired” rate that the neuron uses to encode the animal’s decision on a particular trial.
– the distribution over spike counts given a particular spike rate. This distribution represents “pure noise” reflecting the Poisson-like spiking variability in spike time arrivals, and is to be disregarded / averaged out for purposes of the quantities computed by LIP neurons.
So we can think of this as a kind of “cascade” model: 
The law of total variance states essentially that the total variance of 
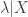


![\mathrm{var}( E[N|X] )](https://s0.wp.com/latex.php?latex=%5Cmathrm%7Bvar%7D%28+E%5BN%7CX%5D+%29&bg=ffffff&fg=333333&s=0&c=20201002)


The authors’ approach to data analysis in this paper is as follows:
- estimate
from data, identifying it with the smallest Fano factor observed in the data. (This assumes that
is zero at this point, so the observed variability is only due to renewal spiking, and ensures varCE is never negative.)
- Estimate
as
in each time bin.
The take-home conclusion is that the variance of 
Comments:
- The assumption of renewal process variability (variance proportional to rate with fixed ratio
-shaped function of spike rate: variance will increase with rate up to a point, but will then go down again to zero as the spike rate bumps up against the refractory period. This would substantially affect the estimates of varCE at high spike rates (making it higher than reported here) This doesn’t seem likely to threaten any of the paper’s basic conclusions here, but it seems a bit worrying to prescribe as a general method.
- Memming pointed out that you could explicitly fit the doubly-stochastic model to data, which would get around making this “renewal process” assumption and provide a much more powerful descriptive model for analyzing the code in LIP. In other words: from the raw spike train data, directly estimate parameters governing the distributions
and
. The resulting model would explicitly specify the stochastic spiking process given
- General philosophical point: the doubly stochastic formulation makes for a nice statistical model, but it’s not entirely clear to me how to interpret the two kinds of stochasticity. Specifically, is the variability in
due to external noise in the moving dots stimulus itself (which contains slightly different dots on each trial), or noise in the responses of earlier sensory neurons that project to LIP? If it’s the former, then
, the spike count, is the vaunted “exponential family with linear sufficient statistics” noise; PPC tells how to read out the spikes to get a posterior distribution over
To sum up, the paper shows an nice analysis of spike count variance in LIP responses, and a cute application of the law-of-total-variance. The doubly stochastic point process model of LIP responses seems ripe for more analysis.
