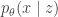In lab meeting this week, we discussed unsupervised learning in the context of deep generative models, namely -variational auto-encoders (-VAEs), drawing from the original, Higgins et al. 2017 (ICLR), and its follow-up, Burgess et al. 2018. The classic VAE represents a clever approach to learning highly expressive generative models, defined by a deep neural network that transforms samples from a standard normal distribution to some distribution of interest (e.g., natural images). Technically, VAE training seeks to maximize a lower bound on the likelihood , where defines the generative mapping from latents to data . This “evidence lower bound” (ELBO) depends on a variational approximation to the posterior, , which is also parametrized by a deep neural network (the so-called “encoder”).
A crucial drawback to the classic VAE, however, is that the learned latent representations tend to lack interpretability. The -VAE seeks to overcome this limitation by learning “disentangled” representations, in which single latents are sensitive to single generative factors in the data and relatively invariant to others (Bengio et al. 2013). I would call these “intuitively robust” — rotating an apple (orientation) shouldn’t make its latent representation any less red (color) or any less fruity (type). To overcome this challenge, -VAEs optimize a modified ELBO given by:
with and standard VAEs corresponding to . The new hyperparameter controls the optimization’s tension between maximizing the data likelihood and limiting the expressiveness of the variational posterior relative to a fixed latent prior .
Recent work has been interested in tuning the latent representations of deep generative models (Adversarial Autoencoders (Makhzani et al. 2016), InfoGANS (Chen et al. 2016), Total Correlation VAEs (Chen et al. 2019), among others), but the generalization used by -VAEs in particular looked somehow familiar to me. This is because -VAEs recapitulate the classical rate-distortion theory problem. This was observed briefly also in recent work by Alemi et al. 2018, but I would like to elaborate and show explicitly how -VAEs are reducible to a distortion-rate minimization using deep generative models.
Rate-distortion theory is a theoretical framework for lossy data compression through a noisy channel. This fundamental problem in information theory balances the minimum permissible amount of information (in bits) transmitted across the channel, the “rate”, against the corruption of the original signal, a penalty measured by a “distortion” function . Our terminology changes, but the fundamental problem is the same; I made that comparison as obvious as possible in the figure below.
Derivation. Given a dataset with a distribution , define any statistical mapping that encodes into a code . Note that is just an encoder, and together they induce a joint distribution with a marginal . The distortion-rate optimization would minimize distortion subject to a maximum rate , i.e.
Consider first the mutual information. We leverage a more tractable upper bound with
We’ve replaced the marginal induced by our choice of encoder with another distribution that makes the optimization more tractable, e.g. in the VAE. Our objective can be rewritten as
Suppose the distortion of interest is posterior density (mis)estimation, . Such a function penalizes representations from which we cannot regenerate an observed data vector through the decoding network with high probability. A typical distortion-rate problem would fix the distortion function, but we choose to learn this decoder. We can optimize the objective for each to eliminate the outer expectation over the data , fix , and recover the -VAE objective precisely:
When , our optimization prioritizes minimizing the second term (rate) over maximizing the first one (distortion). In this sense, the authors’ argument for large can be reinterpreted as an argument for higher-distortion, lower-rate codes (read: latent representations) to encourage interpretability. I edited a figure below from Alemi et al. 2018 to clarify this.
Distortion (D) vs. Rate (R) as a function of free parameters in the rate-distortion problem (and -VAEs) — the proposed method privileges solutions in the top-left quadrant (adapted from Alemi et al. 2018).
Information-theoretic hypotheses abound. Perhaps enforcing optimization in this region could discourage solutions that depend on learning an ultra-powerful decoder (VAE: generator) , in other words solutions that depend on a good code, not necessarily a good decode. Does eliminating this possibility simply make room to fish out an ad-hoc interpretable representation, or is there a more sophisticated explanation waiting to be found? We’ll see.


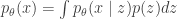
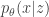


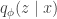
![\underset{\theta,\phi}{\text{maximize}}\:\:\mathbb{E}_{q_\phi(z\mid x)}\left[\log p_\theta(x\mid z)\right]-\beta D_{KL}(q_\phi(z\mid x)\Vert\, p(z))](https://s0.wp.com/latex.php?latex=%5Cunderset%7B%5Ctheta%2C%5Cphi%7D%7B%5Ctext%7Bmaximize%7D%7D%5C%3A%5C%3A%5Cmathbb%7BE%7D_%7Bq_%5Cphi%28z%5Cmid+x%29%7D%5Cleft%5B%5Clog+p_%5Ctheta%28x%5Cmid+z%29%5Cright%5D-%5Cbeta+D_%7BKL%7D%28q_%5Cphi%28z%5Cmid+x%29%5CVert%5C%2C+p%28z%29%29&bg=ffffff&fg=333333&s=0&c=20201002)
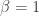
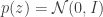
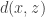

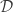
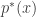
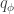


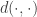

![\underset{q_\phi(z\mid x),p(z)}{\text{minimize}}\:\:\mathbb{E}_{p(x,z)}[d(x,z)]\:\:\text{subject to}\:\: I(x,z)\le R](https://s0.wp.com/latex.php?latex=%5Cunderset%7Bq_%5Cphi%28z%5Cmid+x%29%2Cp%28z%29%7D%7B%5Ctext%7Bminimize%7D%7D%5C%3A%5C%3A%5Cmathbb%7BE%7D_%7Bp%28x%2Cz%29%7D%5Bd%28x%2Cz%29%5D%5C%3A%5C%3A%5Ctext%7Bsubject+to%7D%5C%3A%5C%3A+I%28x%2Cz%29%5Cle+R+&bg=ffffff&fg=333333&s=0&c=20201002)
![\Longrightarrow \underset{q_\phi(z\mid x),p(z)}{\text{minimize}}\:\:\mathbb{E}_{p(x,z)}[d(x,z)]-\beta I(x,z)](https://s0.wp.com/latex.php?latex=%5CLongrightarrow+%5Cunderset%7Bq_%5Cphi%28z%5Cmid+x%29%2Cp%28z%29%7D%7B%5Ctext%7Bminimize%7D%7D%5C%3A%5C%3A%5Cmathbb%7BE%7D_%7Bp%28x%2Cz%29%7D%5Bd%28x%2Cz%29%5D-%5Cbeta+I%28x%2Cz%29&bg=ffffff&fg=333333&s=0&c=20201002)

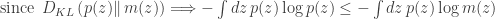
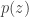
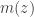
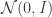
![\underset{q_\phi(z\mid x),m(z)}{\text{minimize}}\:\:\mathbb{E}_{p(x,z)}[d(x,z)]-\beta\, \mathbb{E}_{x\sim\mathcal{D}}\left[D_{KL}(q_\phi(z\mid x)\Vert\, m(z))\right]](https://s0.wp.com/latex.php?latex=%5Cunderset%7Bq_%5Cphi%28z%5Cmid+x%29%2Cm%28z%29%7D%7B%5Ctext%7Bminimize%7D%7D%5C%3A%5C%3A%5Cmathbb%7BE%7D_%7Bp%28x%2Cz%29%7D%5Bd%28x%2Cz%29%5D-%5Cbeta%5C%2C+%5Cmathbb%7BE%7D_%7Bx%5Csim%5Cmathcal%7BD%7D%7D%5Cleft%5BD_%7BKL%7D%28q_%5Cphi%28z%5Cmid+x%29%5CVert%5C%2C+m%28z%29%29%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002)
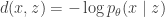
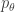
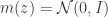
![\underset{q_\phi(z\mid x),p_\theta(x\mid z)}{\text{maximize}}\:\:\mathbb{E}_{q_\phi(z\mid x)}\left[\log p_\theta(x\mid z)\right]-\beta\, D_{KL}(q_\phi(z\mid x)\Vert\, m(z))](https://s0.wp.com/latex.php?latex=%5Cunderset%7Bq_%5Cphi%28z%5Cmid+x%29%2Cp_%5Ctheta%28x%5Cmid+z%29%7D%7B%5Ctext%7Bmaximize%7D%7D%5C%3A%5C%3A%5Cmathbb%7BE%7D_%7Bq_%5Cphi%28z%5Cmid+x%29%7D%5Cleft%5B%5Clog+p_%5Ctheta%28x%5Cmid+z%29%5Cright%5D-%5Cbeta%5C%2C+D_%7BKL%7D%28q_%5Cphi%28z%5Cmid+x%29%5CVert%5C%2C+m%28z%29%29&bg=ffffff&fg=333333&s=0&c=20201002)