We’re now almost a month into 2013, but I wanted to post a brief reflection on our lab highlights from 2012.
Ideas / Projects:
Here’s a summary of a few of the things we’ve worked on:
• Active Learning – Basically: these are methods for adaptive, “closed-loop” stimulus selection, designed to improve neurophysiology experiments by selecting stimuli that tell you the most about whatever it is you’re interested in (so you don’t waste time showing stimuli that don’t reveal anything useful). Mijung Park has made progress on two distinct active learning projects. The first focuses on estimating linear receptive fields in a GLM framework (published in NIPS 2012): the main advance is a particle-filtering based method for doing active learning under a hierarchical receptive field model, applied specifically with the “ALD” prior that incorporates localized receptive field structure (an extension of her 2011 PLoS CB paper). The results are pretty impressive (if I do say so!), showing substantial improvements over Lewi, Butera & Paninski’s work (which used a much more sophisticated likelihood). Ultimately, there’s hope that a combination of the Lewi et al likelihood with our prior could yield even bigger advances.
The second active learning project involves a collaboration with Greg Horwitz‘s group at U. Washington, aimed at estimating the nonlinear color tuning properties of neurons in V1. Here, the goal is to estimate an arbitrary nonlinear mapping from input space (the 3D space of cone contrasts, for Greg’s data) to spike rate, using a Gaussian Process prior over the space of (nonlinearly transformed) tuning curves. This extends Mijung’s 2011 NIPS paper to examine the role of the “learning criterion” and link function in active learning paradigms (submitted to AISTATS) and to incorporate response history and overdispersion (which occurs when spike count variance > spike count mean) (new work to be presented at Cosyne 2013). We’re excited that Greg and his student Patrick Weller have started collecting some data using the new method, and plan to compare it to conventional staircase methods.
• Generalized Quadratic Models – The GQM is an extension of the GLM encoding model to incorporate a low-dimensional quadratic form (as opposed to pure linear form) in the first stage. This work descends directly from our 2011 NIPS paper on Bayesian Spike-Triggered Covariance, with application to both spiking (Poisson) and analog (Gaussian noise) responses. One appealing feature of this setup is the ability to connect maximum likelihood estimators with moment-based estimators (response-triggered average and covariance) via a trick we call the “expected log-likelihood“, an idea on which Alex Ramirez and Liam Paninski have also done some very elegant theoretical work.
Basically, what’s cool about the GQM framework is that it combines a lot of desirable things: (1) ability to estimate a neuron’s (multi-dimensional, nonlinear) stimulus dependence very quickly when stimulus distribution is “nice” (like STC and iSTAC); (2) achieve efficient performance when stimulus distribution isn’t “nice” (like MID / maximum-likelihood); (3) incorporate spike history (like GLM), but with quadratic terms (making it more flexible than GLM, and unconditionally stable); (4) apply to both spiking and analog data. The work clarifies theoretical relationships between moment-based and likelihood-based formulations (novel, as far as we know, for the analog / Gaussian noise version). This is joint work with Memming, Evan & Nicholas Priebe. (Jonathan gave a talk at SFN; new results to be presented at Cosyne 2013).
• Modeling decision-making signals in parietal cortex (LIP) – encoding and decoding analyses of the information content of spike trains in LIP, using a generalized linear model (with Memming and Alex Huk; presented in a talk by Memming at SFN 2012). Additional work by Kenneth and Jacob on Bayesian inference for “switching” and “diffusion to bound” latent variable models for LIP spike trains, using MCMC and particle filtering (also presented at SFN 2012).
• Non-parametric Bayesian models for spike trains / entropy estimation – Evan Archer, Memming Park and I have worked on extending the popular “Nemenman-Schafee-Bialek” (NSB) entropy estimator to countably-infinite distributions (i.e., cases where one doesn’t know the true number of symbols). We constructed novel priors using mixtures of Dirichlet Processes and Pitman-Yor Processes, arriving at what we call a Pitman-Yor Mixture (PYM) prior; the resulting Bayes least-squares entropy estimator is explicitly designed to handle data with power-law tails (first version published in NIPS 2012.) We have some new work in this vein coming up at Cosyne, with Evan & Memming presenting a poster that models multi-neuron spike data with a Dirichlet process centered on a Bernoulli model (i.e., using a Bernoulli model for the base distribution of the DP). Karin Knudson will present a poster about using the hierarchical Dirichlet process (HDP) to capture the Markovian structure in spike trains and estimate entropy rates.
• Bayesian Efficient Coding – new normative paradigm for neural coding, extending Barlow’s efficient coding hypothesis to a Bayesian framework. (Joint work with Memming: to appear at Cosyne 2013).
• Coding with the Dichotomized Gaussian model – Ozan Koyluoglu has been working to understand the representational capacity of the DG model, which provides an attractive alternative to the Ising model for describing the joint dependencies in multi-neuron spike trains. The model is known in the statistics literature as the “multivariate probit”, and it seems there should be good opportunities for cross-pollination here.
• Other ongoing projects include spike-sorting (with Jon Shlens, EJ Chichilnisky, & Eero Simoncelli), prior elicitation in Bayesian ideal observer models (with Ben Naecker), model-based extensions of the MID estimator for neural receptive fields (with Ross Williamson and Maneesh Sahani), Bayesian models for biases in 3D motion perception (with Bas Rokers), models of joint choice-related and stimulus-related variability in V1 (with Chuck Michelson & Eyal Seidemann; to be presented at Cosyne 2013), new models for psychophysical reverse correlation (with Jacob Yates), and Bayesian inference methods for regression and factor analysis in neural models with negative binomial spiking (with James Scott, published in NIPS 2012).
Conferences: We presented our work this year at: Cosyne (Feb: Salt Lake City & Snowbird), CNS workshops (July: Atlanta), SFN (Oct: New Orleans), NIPS (Dec: Lake Tahoe).
Reading Highlights:
- In the fall, we continued (re-started) our reading group on Non-parametric Bayesian models, focused in particular on models of discrete data based on the Dirichlet Process, in particular: Hierarchical Dirichlet Processes (Teh et al) and the Sequence Memoizer (Wood et al).
- Kenneth has introduced us to Riemannian Manifold HMC and Hybrid Monte Carlo and some other fancy Bayesian inference methods, and is preparing to tell us about some implementations (using CUDA) that allow them to run super fast on the GPU (if you have an nvidia graphics card).
- We enjoyed reading Simon Wood’s paper (Nature 2010), about “simulated likelihood methods” for doing statistical inference in systems with chaotic dynamics. Pretty cool idea, related to the Method of Simulated Moments, that he applies to some crazy chaotic (but simple) nonlinear models from population ecology. Seems like an approach that might be useful for neuroscience applications (where we also have biophysical models described by nonlinear ODEs for which inference difficult!)
Milestones:
- Karin Knudson: new lab member (Ph.D. student in mathematics), joined during fall semester.
- Kenneth Latimer & Jacob Yates: passed INS qualifying exams
- Mijung Park: passed Ph.D. qualifying exam in ECE.



 (“global measure” sampled from DP with base measure
(“global measure” sampled from DP with base measure  and concentration
and concentration  ).
). (sequence of conditionally independent random measures with common base measure
(sequence of conditionally independent random measures with common base measure  , e.g.,
, e.g., 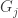 are distributions over clusters from data collected on different days)
are distributions over clusters from data collected on different days)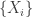 from distribution
from distribution 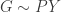 with G marginalized out.
with G marginalized out. explicitly, using iid draws of Beta random variables to obtain stick weights
explicitly, using iid draws of Beta random variables to obtain stick weights 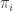 .
. denote the external (“task”) variables on a single trial (motion stimulus, saccade direction, etc), let
denote the external (“task”) variables on a single trial (motion stimulus, saccade direction, etc), let 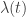 denote the time-varying (“command”) spike rate on that trial, and let
denote the time-varying (“command”) spike rate on that trial, and let  represent the actual (binned) spike counts. The model specifies the final distribution over spike counts
represent the actual (binned) spike counts. The model specifies the final distribution over spike counts 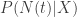 in terms of two underlying distributions (hence “doubly stochastic”):
in terms of two underlying distributions (hence “doubly stochastic”): – the distribution over rate given the task variables. This is the primary object of interest;
– the distribution over rate given the task variables. This is the primary object of interest;  is the “desired” rate that the neuron uses to encode the animal’s decision on a particular trial.
is the “desired” rate that the neuron uses to encode the animal’s decision on a particular trial. – the distribution over spike counts given a particular spike rate. This distribution represents “pure noise” reflecting the Poisson-like spiking variability in spike time arrivals, and is to be disregarded / averaged out for purposes of the quantities computed by LIP neurons.
– the distribution over spike counts given a particular spike rate. This distribution represents “pure noise” reflecting the Poisson-like spiking variability in spike time arrivals, and is to be disregarded / averaged out for purposes of the quantities computed by LIP neurons. , where each of those arrows implies some kind of noisy encoding process.
, where each of those arrows implies some kind of noisy encoding process. is the sum of the “rate” variance of
is the sum of the “rate” variance of 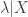 and the average point-process variance
and the average point-process variance  , averaged across
, averaged across  . Technically, the first of these (the quantity of interest here) is called the “variance of the conditional expectation” (or varCE, as it says on the t-shirt)—this terminology comes from the fact that
. Technically, the first of these (the quantity of interest here) is called the “variance of the conditional expectation” (or varCE, as it says on the t-shirt)—this terminology comes from the fact that ![\mathrm{var}( E[N|X] )](https://s0.wp.com/latex.php?latex=%5Cmathrm%7Bvar%7D%28+E%5BN%7CX%5D+%29&bg=ffffff&fg=333333&s=0&c=20201002) . The approach taken here is to assume that spiking process
. The approach taken here is to assume that spiking process  . For a Poisson process, we would have
. For a Poisson process, we would have  , since variance is equal to mean.
, since variance is equal to mean. from data, identifying it with the smallest Fano factor observed in the data. (This assumes that
from data, identifying it with the smallest Fano factor observed in the data. (This assumes that  is zero at this point, so the observed variability is only due to renewal spiking, and ensures varCE is never negative.)
is zero at this point, so the observed variability is only due to renewal spiking, and ensures varCE is never negative.) as
as  in each time bin.
in each time bin. (i.e., the varCE), is consistent with
(i.e., the varCE), is consistent with  -shaped function of spike rate: variance will increase with rate up to a point, but will then go down again to zero as the spike rate bumps up against the refractory period. This would substantially affect the estimates of varCE at high spike rates (making it higher than reported here) This doesn’t seem likely to threaten any of the paper’s basic conclusions here, but it seems a bit worrying to prescribe as a general method.
-shaped function of spike rate: variance will increase with rate up to a point, but will then go down again to zero as the spike rate bumps up against the refractory period. This would substantially affect the estimates of varCE at high spike rates (making it higher than reported here) This doesn’t seem likely to threaten any of the paper’s basic conclusions here, but it seems a bit worrying to prescribe as a general method. and
and  . The resulting model would explicitly specify the stochastic spiking process given
. The resulting model would explicitly specify the stochastic spiking process given  due to external noise in the moving dots stimulus itself (which contains slightly different dots on each trial), or noise in the responses of earlier sensory neurons that project to LIP? If it’s the former, then
due to external noise in the moving dots stimulus itself (which contains slightly different dots on each trial), or noise in the responses of earlier sensory neurons that project to LIP? If it’s the former, then  , the spike count, is the vaunted “exponential family with linear sufficient statistics” noise; PPC tells how to read out the spikes to get a posterior distribution over
, the spike count, is the vaunted “exponential family with linear sufficient statistics” noise; PPC tells how to read out the spikes to get a posterior distribution over 