Last Thursday we discussed how to fit psychophysical reverse correlation kernels using logistic regression, regularized by using an L1 prior over a basis vectors defined by a Laplacian pyramid (Mineault et al 2009). In psychophysical reverse correlation, a signal is embedded in noise and the observer’s choices are correlated with the fluctuations in the noise, revealing the underlying template the observer is using to do the task. Traditionally this is done by sorting the choices — as hits, misses, false alarms correct rejects — and averaging across the noise frames for each set of choices, then subtracting the average noise frame for the misses and correct rejects from the hits and false alarms. The resulting kernel is the size (space x space x time) of the stimulus, which becomes high-dimensional fast and therefore requires a lot of trials to get enough data. As an alternative, one can use maximum likelihood to do logistic regression and apply priors to reduce the number of trials required:
maximize 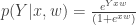 , where Y is the observer’s responses, x is a matrix of the stimulus (trials x stimulus vector) augmented by a column of ones (for the observer’s bias), and w is the observer’s kernel (size = [1 x(1,:)]). Using a sparse prior (L1 norm) over a set of smooth basis (defined by a laplacian pyramid) reduces the number of trials required to fit the kernel while adding only one hyperparameter. The authors use simulations and real psychophysical data to fit an observer’s psychophysical kernel and their code is available here.
, where Y is the observer’s responses, x is a matrix of the stimulus (trials x stimulus vector) augmented by a column of ones (for the observer’s bias), and w is the observer’s kernel (size = [1 x(1,:)]). Using a sparse prior (L1 norm) over a set of smooth basis (defined by a laplacian pyramid) reduces the number of trials required to fit the kernel while adding only one hyperparameter. The authors use simulations and real psychophysical data to fit an observer’s psychophysical kernel and their code is available here.

