
This week, we talked about how to deal with hyperparameters in Bayesian hierarchical models, by reading the paper: “Hyperparameters, optimize or integrate out?” by David MacKay (in Maximum entropy and Bayesian methods, 1996).
The basic setup as follows. We have a model for data 

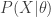
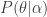

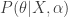
- Evidence approximation (EA) – finds the hyperparameters
that maximize the evidence
. The optimized hyperparameters are then “fixed” so that the posterior takes the form
. (Note this is a form of Empirical Bayes parameter estimation, where the prior is estimated from the data and then used to regularize the parameter estimate). Since the two terms on the right are Gaussian, the posterior is truly Gaussian if
- MAP method – involves integrating out the hyperparameters to obtain the true posterior
. (This involves assuming a prior over
The paper claims the latter method is much worse. The Laplace approximation will in general produce a much-too-narrow posterior if there’s a spike at zero in the true posterior, which will often arise if the problem is ill-posed (i.e., the likelihood is nearly flat in some directions, placing no constraints on the parameters in that subspace). There are some arguments about the effective number of free parameters and “effective
